Blog
Engineering Intuition at Scale: The Architecture of Agentic Code Review
Dec 15, 2025
Omri Levy
.png)
Code reviews have many incentives; the most popular are catching bugs, improving code quality, proposing alternative solutions, and spreading knowledge within the team. Catching bugs is the most important - and also the hardest to achieve.
In this post, we’ll take a hard look at how today’s AI coding agents actually perform as reviewers. We benchmarked multiple tools against real-world PRs that shipped bugs into production. The results were clear: generalist AI code agents catch some issues, but they consistently miss the hardest ones-the same kinds of regressions human reviewers struggle with.
That failure (and a production bug our team missed in our own code) is what led us to explore and implement a different agentic design with critical implications for AI Code Review. Instead of relying on a predefined workflow missing critical code base ‘interaction’, we shifted to a multi-agent architecture that can query and engage with a code base. By breaking reviews into phases-context mapping, intent inference, Socratic questioning, and targeted investigations-we built an agentic reviewer that reasons more like a senior engineer and produces consistent results.
In the sections that follow, we’ll cover:
Often AI code reviewers are limited by only using the diff as input. They annotate changed lines, peek at nearby context, and sometimes run pattern checks. That’s helpful, but it misses the class of defects that manifest outside the immediate change: schema mismatches, cross-service drift, edge-case paths not exercised by tests, and violations of implicit team norms.
Thesis: If a reviewer cannot (a) infer author intent, (b) trace impacts beyond the diff, and (c) prove or disprove specific risks with evidence, it will miss the bugs that cause incidents.
The report: how existing tools fared (jump ahead to see a few of the key test challenges and results per tooling here)
Before building anything new, we stress-tested the current crop of AI coding agents on real PRs that actually shipped bugs.
Dataset (real-world PRs, not contrived):
AI Coding agents tested (with their recommended configs):
See the details of a few of the key test challenges and results per tooling here
Results (8 cases total):
Not terrible, but every tool missed the hardest defects-the same ones humans missed. For example, the cross-service schema drift case is emblematic: it required reading across two services, unnesting schemas, and validating that consumers were updated. Every agent whiffed. Worse, results were inconsistent. Same setup, different runs, different answers.
The report made one thing obvious. If you want consistent detection of cross-cutting risks, you need a reviewer that reasons like a senior engineer.
We designed Baz’s Agentic Reviewer to mirror how experienced engineers actually review: map context, infer intent, ask hard questions, then investigate until there is a verdict.
Design goals
The review flow
Imagine this as a graph: the first node collects insights and questions; downstream nodes are specialized investigators; the final node consolidates verdicts with a reflection, like a quality check that confirms the verdict is good enough.
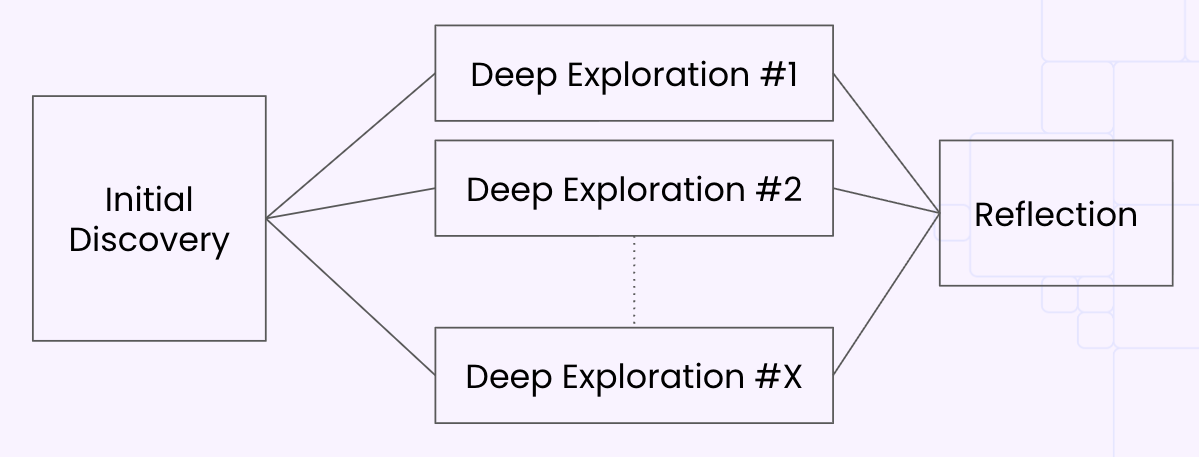
Architecture at a glance
When we went back to test the results on the same benchmark, something pretty cool happened:
This is not generic code analysis. It is engineering intuition made systematic. Instead of walls of AI text, you get a short list of high-leverage risks with evidence and explicit “safe” validations for everything else. That makes reviews faster, outcomes clearer, and trust higher.
To reduce flakiness, we built real-world, non-trivial fixtures we know inside out, with expected behavior defined at each step. That turns intuition into repeatable checks:
Other AI reviewers flood you with verbose commentary that’s hard to parse. The Agentic Reviewer takes the opposite approach: minimalism over noise. Instead of walls of speculation, you get a handful of explicit verdicts, backed by evidence. Fewer findings, but each one is higher signal and tied directly to the risks that matter.
That’s the real shift: this isn’t just static code analysis dressed up with an LLM. It’s turning engineering intuition into a systematic, repeatable process. By breaking reviews into phases and proving or disproving specific risks, agentic reviewers help teams move faster, merge with confidence, and avoid the outages that sneak past rules and linters.
Confidence in merging requires more than rules, tests, and luck. The future of code review is agentic-intuition made systematic, not noise made louder.
👉 See the Agentic Reviewer in action


.png)
