Blog
5 Ways to Measure the Impact of AI Code Review
How to track outcomes, developer sentiment, and real ROI for your AI
Aug 17, 2025
Guy Eisenkot
How to track outcomes, developer sentiment, and real ROI for your AI

AI agents are creeping into more codebases every month. Teams see the promise: catching subtle issues earlier, enforcing consistent standards, and freeing up human reviewers for the hard calls.
But every conversation I’ve had with a VP of Engineering or Staff Engineer eventually lands on the same question:
“How do we know it’s working?”
It turns out measuring AI code review impact is harder than generating the comments in the first place. Traditional accuracy metrics don’t map well to human workflows. Developers are skeptical until they see the value in their own PRs. And engineering leaders need something better than vanity metrics to justify rolling this out org-wide.
At Baz, we’ve spent the last year obsessing over this exact problem. By tracking key metrics like developer sentiment and whether AI‑flagged issues actually get resolved, teams can finally see if an agent is pulling its weight. The hard part isn’t flagging code issues. It’s measuring how those suggestions land with real developers in the context of each pull request.
Here’s what we’ve learned about measuring AI code review in a way that actually builds confidence and how we’re putting that into practice in Baz’s Code Review Evaluations.
Background: How Baz Deploys Code Review Agents
At Baz, every AI reviewer is designed to capture and apply the hard‑won judgment that normally lives in your team’s PR threads. Our agents aren’t just generic linters, they’re specialized reviewers, each focused on a language or subdomain your team cares about.
Whenever an agent leaves a comment on a pull request, Baz records the entire interaction: the code context, the human response, and the outcome of that suggestion. Over time, this creates a living corpus of review conversations, a feedback loop that powers our Evaluations. This foundation lets us track which suggestions developers act on, how they feel about the feedback, and how each reviewer evolves with your team’s standards.
This evaluation loop is what makes AI code review measurable. By analyzing outcomes, sentiment, and reviewer behavior over time, we can move beyond vanity metrics and start answering the only question that matters: Is the AI actually helping developers?
Here are the five key ways that we do this at Baz, and what we believe is the most effective way to measure it.
The first trap teams fall into is tracking how much the AI talks.
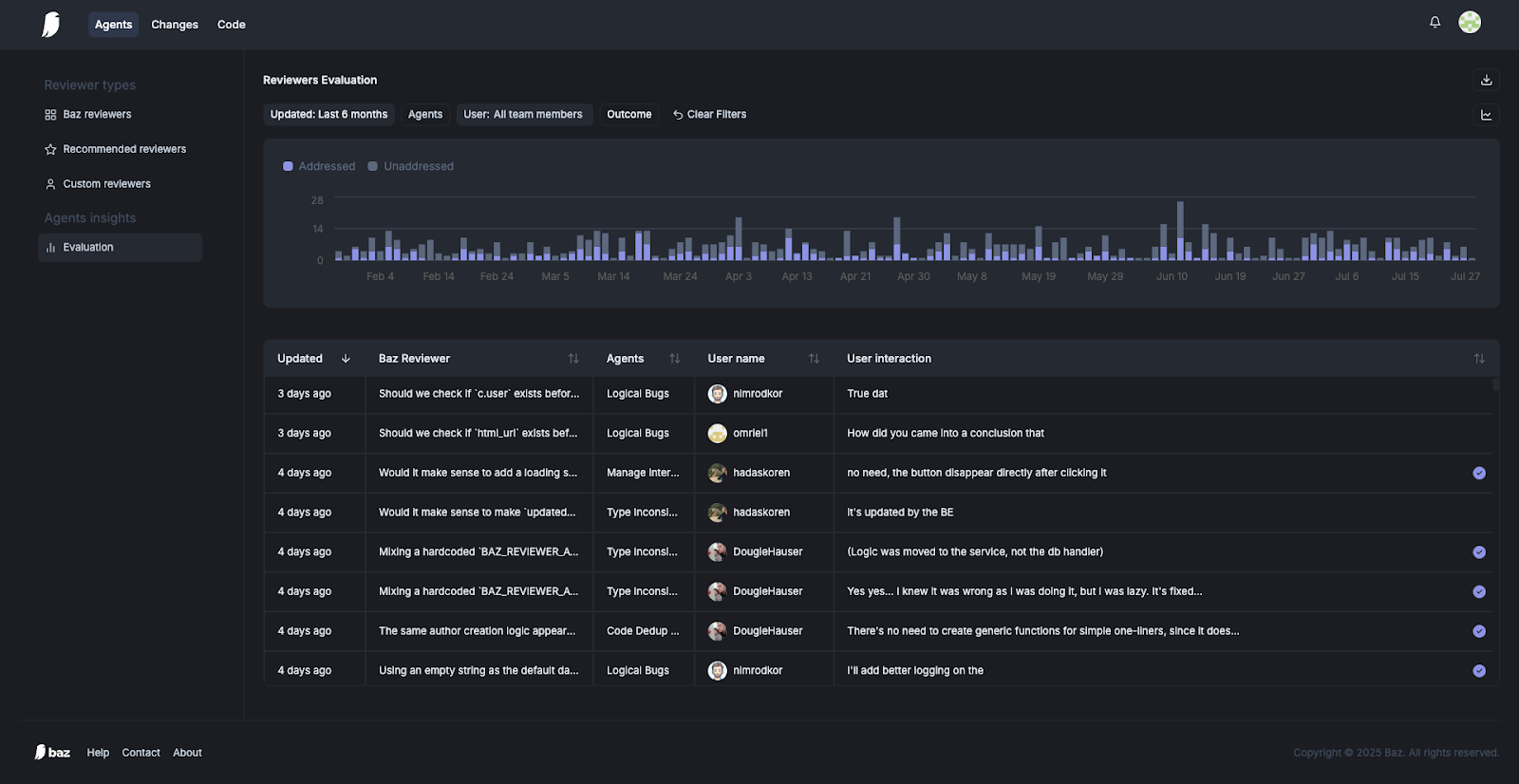
The first step in measuring AI code review is focusing on what actually happens after the AI leaves a comment. Did a developer act on the AI’s suggestion? We call this an outcome-first evaluation. Every AI comment in Baz is automatically classified as:
This outcome-first view gives teams a real acceptance rate, showing which reviewers are catching meaningful issues and which are creating noise. Over time, these trends are a far more honest KPI than anything labeled “accuracy.”
By classifying every comment this way, teams can see a true acceptance rate for each AI reviewer. A high addressed percentage signals that the AI is catching real issues that developers fix. A cluster of unaddressed or rejected comments usually means the agent is producing false positives or low‑value feedback.
Evaluations in Baz aggregate this data over time and visualize it as addressed vs. unaddressed trends. This lets engineering leaders:
Because most teams deploy multiple reviewers, each with a specific focus - like security, performance, or code style - Baz also makes it easy to filter and drill down:
Outcome‑based tracking shifts the conversation from “Did the AI comment?” to “Did it help?. A far more meaningful KPI for both developers and engineering leaders.
Even a technically correct AI comment can fail if developers resent it or worse, silently ignore it. That’s why tracking developer sentiment is as important as tracking outcomes. Evaluations first help answer the key question of how the AI agents are actually helping developers. Positive sentiment and addressed outcomes together are strong signals that the AI reviewer is adding value.
In Baz, sentiment is inferred directly from the pull request conversation. Each discussion thread is classified as:
This sentiment metric reveals how the AI’s feedback is actually received by humans in the loop, not just how many comments were left.
Why does this matter? Because sentiment plus outcomes tell the whole story:
Baz Evaluations present sentiment and outcome metrics side by side so teams can quickly spot these patterns. For example:
By layering sentiment over outcomes, teams can move beyond superficial metrics and see where AI is helping, where it’s hurting, and where it’s just noise.
Static linters don’t learn. They make the same comment forever, whether it helps or not. AI code reviewers can and should do better.
The biggest advantage of agentic code review is that every developer interaction is an opportunity to teach the AI. Baz captures these lessons through a feature we call Reviewer Memory, turning raw pull request conversations into actionable improvements.
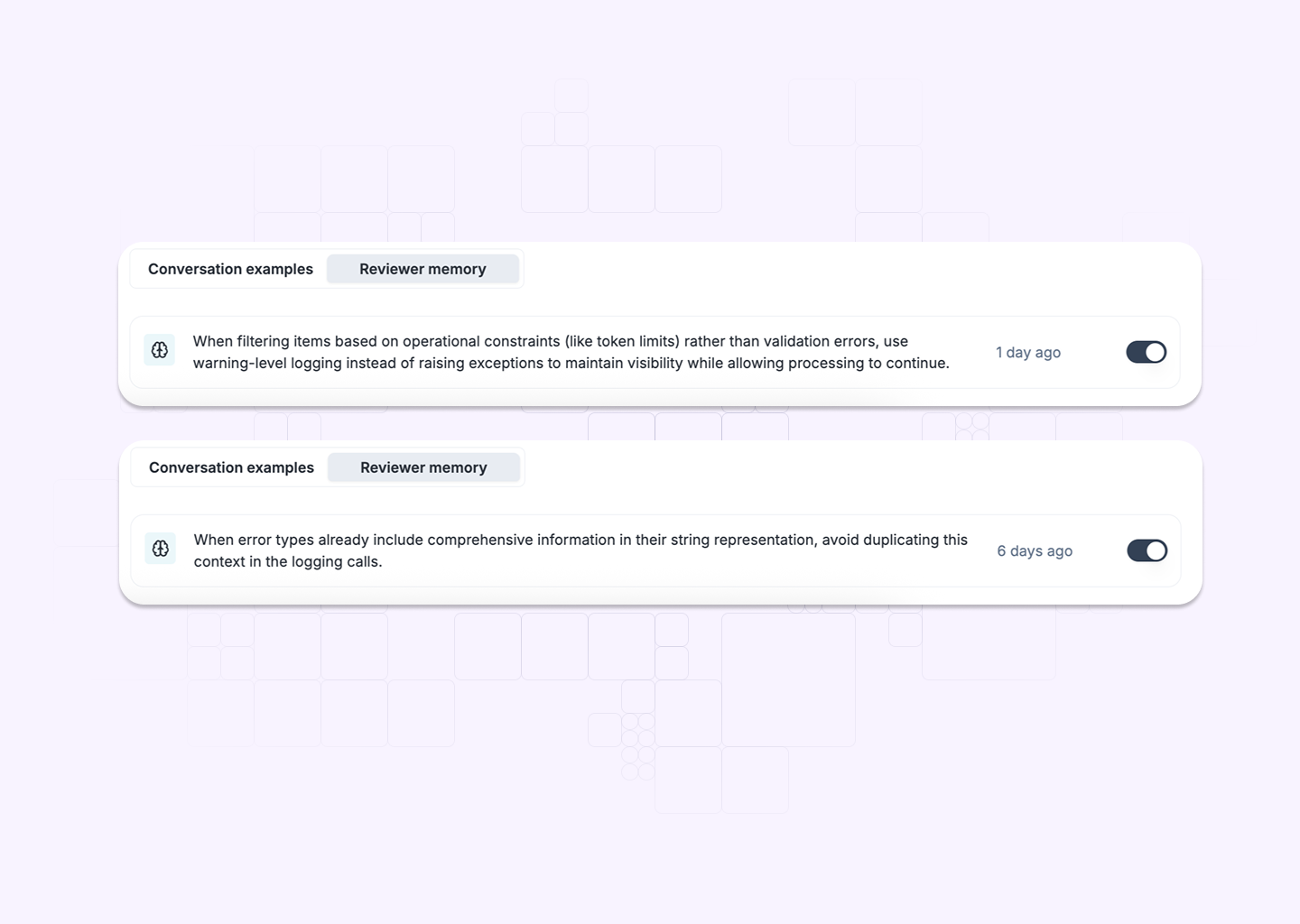
Here’s how it works:
This continuous improvement loop transforms the AI from a static assistant into a living, team‑aligned reviewer. Over time, it:
The more your team engages with the AI, the smarter and more aligned it becomes. It’s a virtuous cycle: developer feedback → reviewer memory → better AI → higher impact.
One of the biggest lessons we have learned building Baz is that AI reviewers need to evolve just like your codebase does. A static prompt quickly becomes stale; an adaptive reviewer gets sharper with every iteration.
In Baz, every reviewer (agent) is defined by a prompt, a set of rules and instructions that guide its code review behavior. We treat that prompt like versioned code:
This versioning approach encourages an engineering discipline to prompt management:
Over time, this builds institutional knowledge into the AI itself. For example:
Encoding these norms into prompts ensures every pull request gets consistent, standards-aligned review, scaling the judgment of your best engineers across the organization.
In short, prompt versioning turns AI reviewers into living, auditable teammates that learn from your codebase and improve with every iteration.
Developers are a discerning audience. AI feedback has to be precise, respectful, and genuinely useful, or it quickly becomes noise. When building Baz, we put significant effort into UX research and prompt design to make sure our AI reviewers feel like a helpful teammate instead of a bossy linter.
Tone and voice matter. Each reviewer is instructed to communicate like a friendly colleague, never a directive authority. Comments are phrased as short, suggestive nudges like “Have you considered…?” rather than “This is wrong.” The goal is for developers to feel assisted, not criticized.
Brevity and focus are just as important. Baz reviewers are limited to concise, high-impact comments, often no more than two short sentences. Silence is encouraged if nothing meaningful or certain is found. This ensures attention is only drawn to the few issues that really matter.
Actionability is the third pillar. Every comment should lead to a clear next step or code improvement. We avoid vague warnings or generic praise, and we encourage reviewers to include just enough context for the developer to understand and act without extra friction.
Finally, minimal disruption is part of the design. Baz comments appear in pull requests like any human review, and our Evaluations interface is filterable and lightweight so team leads can see trends without wading through irrelevant data. Early user testing confirmed that developers respond better to feedback that is infrequent, high-quality, and collegial.
The result is an AI reviewer that earns trust by being useful, quiet when it should be, and respectful of a developer’s time.
For teams adopting Baz, Evaluations provide a clear, data-driven way to measure AI’s contribution to code review. Engineering leaders can see exactly how many AI comments led to code changes and how developers responded over time. This visibility builds confidence by showing concrete outcomes, such as “Our AI reviewer caught 37 critical issues last quarter, 30 of which were fixed with mostly positive developer feedback.”
AI code review is not a replacement for human judgment. It is a force multiplier for organizations that have invested in capturing institutional knowledge and embedding it in their codebase. Developers remain in control: they choose whether to act on each comment, and those choices feed back into the Evaluations system to make the AI smarter with every pull request.
The result is a continuously improving code review assistant that saves developer time, raises code quality, and adapts to the team’s evolving standards.
