Blog
Baz #1 in Precision in independent Code Review Bench
Baz #1 in Precision in independent Code Review Bench
Mar 29, 2026
Guy Eisenkot
Baz #1 in Precision in independent Code Review Bench
.png)
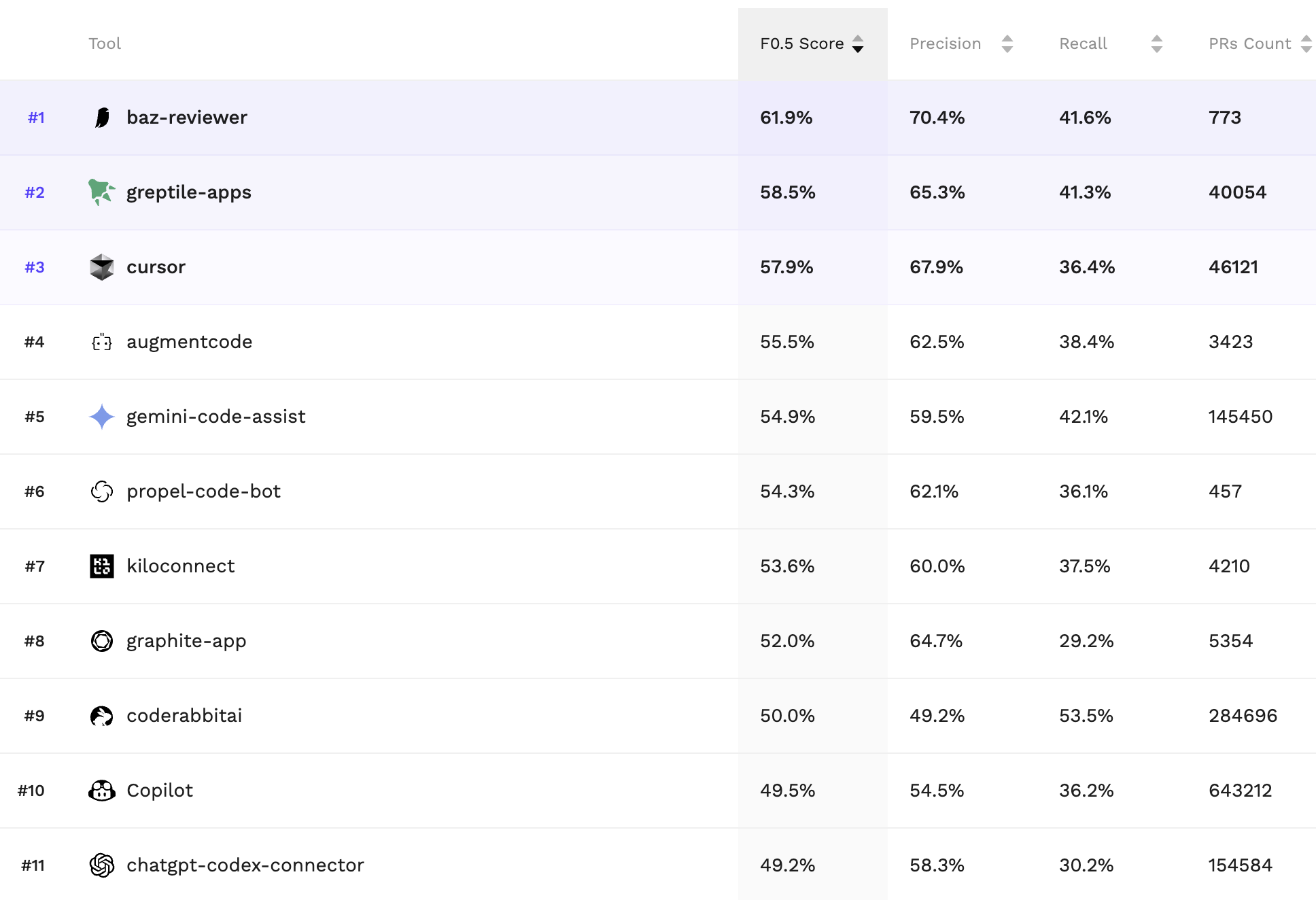
Today, Martian is launching Code Review Bench, an independent benchmark that measures how effective automated code review tools are in practice. Baz ranks #1 in precision in the current results, with strong overall performance as the benchmark evolves.
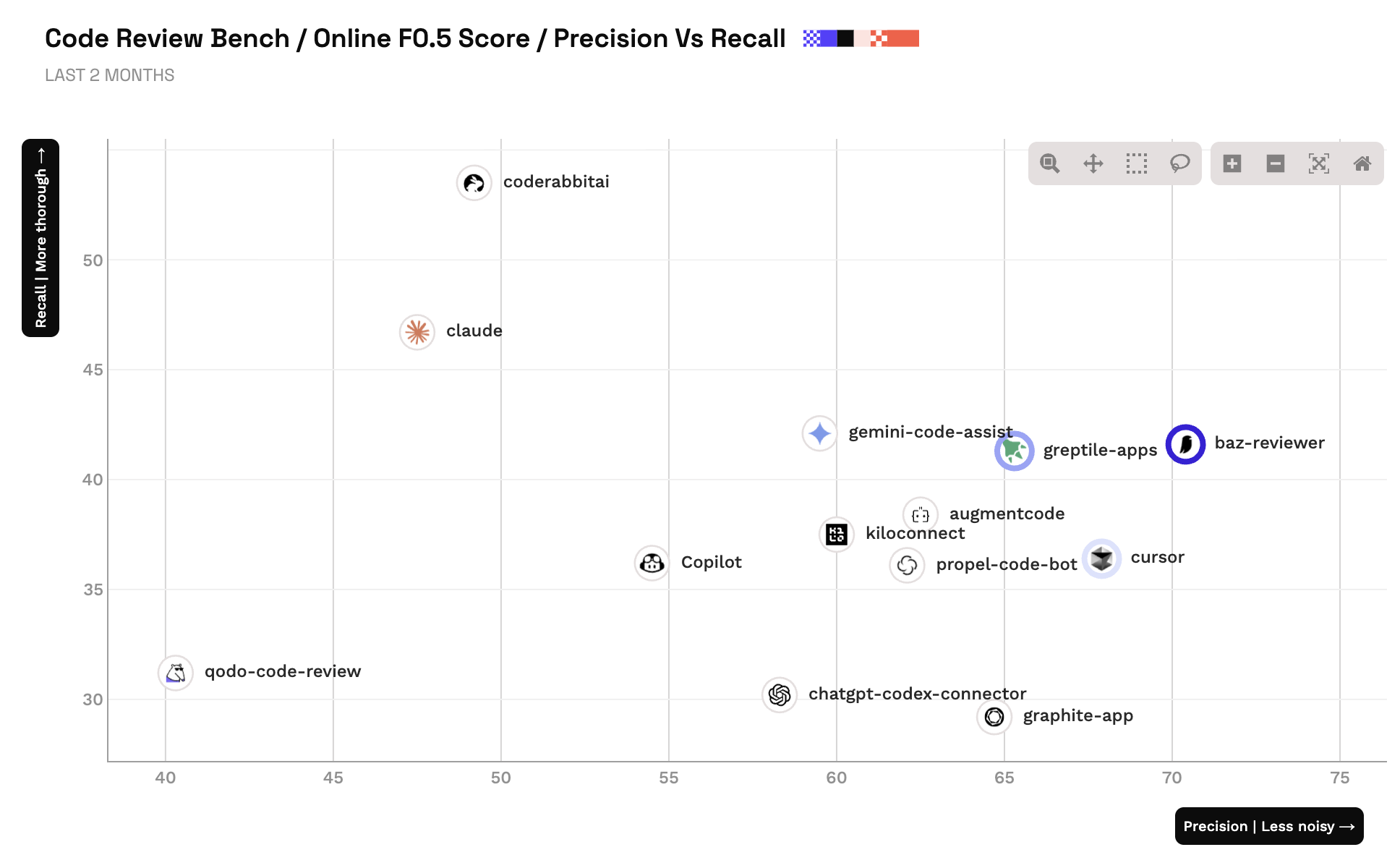
Precision is the metric we optimize for. If a reviewer is noisy, teams ignore it. If it is high-signal, it becomes part of the workflow.
The benchmark exists because code review has an evaluation problem. Its increasingly important but harder and harder to measure because of the rate of development of models and coding form factors.
Many previous “benchmarks” in this category are too small to generalize, too static to stay clean, and too tied to a single vendor’s scoring choices. Martian’s approach is to treat benchmarking as a living system, not a one-off report.
At a high level, the benchmark combines two ideas:
The goal is simple: keep the measurement aligned with what developers value, and keep it refreshable so it does not get stale. This is the direction the field needs.
Legacy rule-based code review failed in a predictable way: It starts useful with plenty of signal but then, over time, becomes noise. Reviewers start to scroll past it and find ways to comment it out. Soonafter teams stop trusting it, and whatever recall the tool had stops mattering because the signal no longer impacts quality.
We always believed that when we flag fewer items but they are consistently worth attention, it changes developer behavior: It reduces review load, accelerates merges, and makes teams more willing to let AI propose larger changes because verification is reliable.
Baz was designed around a practical constraint: review bandwidth.
The fastest way to lose review bandwidth is to ask for attention too often. The fastest way to earn it is to be right when it matters.
So we optimize for:
Baz tries to emit comments only when they cross a usefulness threshold. That means we are willing to miss marginal suggestions if the alternative is training developers to ignore the tool.
When Baz flags an issue, it should be obvious what code is implicated and why the issue matters. Review is a communication problem as much as a detection problem.
Teams disagree about what “good” means. A benchmark that treats all teams as identical ends up scoring tools on a definition nobody asked for. We think the future of review is configurable and spec-driven, and benchmarking needs to move in that direction.
Precision is the first-order signal that these choices are working.
Two things can be true at the same time:
Code Review Bench is explicit about iteration and refresh, which is the correct stance. We will treat this result the same way: as a strong signal, not a final verdict.
The outcome we care about is not a static placement on a leaderboard. It is sustained performance as the benchmark updates, datasets refresh, and evaluation improves.
We are using this moment for two concrete things.
Precision is the adoption gate, but it is not the only metric that matters. As the benchmark adds stronger recall measurement, better grounding, and richer definitions of what counts as a bug, we want Baz to remain high-signal while expanding coverage in a way teams still trust.
Benchmarks become standards when tool builders take them seriously, challenge them, and help shape the interface. A shared evaluation harness, consistent output formats, and transparent methodology are how this category matures.
We want that maturity. Review is the verifier for code generation, and verification is a lever for everything that comes next.
If you are evaluating automated code review tools, you can look at the benchmark results and then test the claims in your own environment.
If you find failure modes, edge cases, or categories where you want Baz to be stricter or quieter, tell us. The goal is not to “win” a single benchmark run. The goal is to build a reviewer that teams keep enabled.

.png)
.png)
.png)